오늘부터 혼자 공부하는 머신러닝으로 공부하고 여기에 정리글을 쓰려고 합니다.
처음 공부하는 소재는 KNN 알고리즘을 이용한 생선 분류입니다.
우선 KNN 알고리즘이란 K-Nearest Neighbor 의 약자로, 가장 인접한 k개의 데이터를 토대로
새로운 값을 분류해주는 알고리즘입니다. 사실 이 방법은 model을 훈련시키는게 아니라,
학습한 모든 데이터를 저장하고 있다가 새로운 값이 들어오면 거리계산을 통해 k개중 비중이 높은걸
출력해주는 형식입니다. 거리를 계산할 땐, 맨해튼 거리나 유클리드 거리등 다양한 방법이 존재합니다.
또한 k 값 또한 우리가 적절히 정해줄 수 있습니다. 이 방법의 장점은 매우 간단하고 직관적입니다.
그리고 효율도 꽤나 잘 나옵니다. 하지만 새로운 데이터가 들어오면 모든 데이터와의 거리를 계산해서
k개를 뽑아야하다보니 시간이 오래 걸립니다. 그리고 거리를 잴 때, 그냥 계산을 하면 안됩니다.
정규화를 통해 상대적 크기에 대한 영향력을 최대한 줄여야 합니다. 이제 실습을 진행합니다.
목표는 도미와 빙어의 데이터를 토대로 새로운 데이터를 예측할 것 입니다.
우선 도미의 데이터와 빙어의 데이터를 가져와서 산점도를 그리면 아래와 같습니다.
# 도미, 빙어 데이터
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()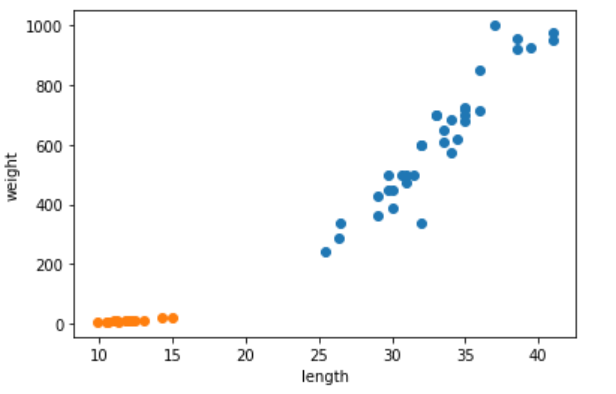
이제 학습데이터를 만들기 위해 두 데이터를 길이와 무게별로 합치고 [l, w] 꼴로 만들어줍니다.
length=bream_length+smelt_length
weight=bream_weight+smelt_weight
fish_data=[[l,w] for l, w in zip(length, weight)]
이제 이진 분류를 해봅시다. 도미를 1로, 빙어를 0으로 하여 학습용 정답 데이터를 만들어줍니다.
아까 합칠 때, 도미의 데이터에 빙어의 데이터를 합쳤으므로, 처음 35개의 값에는 1을,
나머지 14개의 값에는 0을 부여해주면 됩니다.
# 도미면 1, 빙어면 0 만드는 정답 데이터
fish_target=[1]*35+[0]*14
이제 사이킷런의 KNN 모델을 import하고 사용해줍니다.
사이킷런의 대표적인 method으로는,
fit() : 사이킷런 모델을 훈련할 때 사용합니다.
predict() : 훈련한 모델을 예측할 때 사용합니다.
score() : 훈련한 모델의 성능을 측정합니다.
from sklearn.neighbors import KNeighborsClassifier
KNN=KNeighborsClassifier() # 객체 생성 # k기본값 5
# kn=KNeighborsClassfier(n_neighbors=x) k=x로 설정
KNN.fit(fish_data, fish_target) # fit을 통해 훈련
print(KNN.predict([[30, 700]]))
print(KNN.predict([[17, 21]]))
이에 대한 결과는 아래와 같습니다.
[1]
[0]
이를 통해 새로운 데이터가 들어올 때 잘 분류해줌을 알 수 있습니다.
전체 코드입니다.
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
# 도미, 빙어 데이터
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
plt.scatter(bream_length, bream_weight)
plt.scatter(smelt_length, smelt_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
# 두 데이터 합치기
length=bream_length+smelt_length
weight=bream_weight+smelt_weight
fish_data=[[l,w] for l, w in zip(length, weight)]
# 도미면 1, 빙어면 0 만드는 정답 데이터
fish_target=[1]*35+[0]*14
KNN=KNeighborsClassifier() # 객체 생성 # k기본값 5
# kn=KNeighborsClassfier(n_neighbors=x) k=x로 설정
KNN.fit(fish_data, fish_target) # fit을 통해 훈련
print(KNN.predict([[30, 700]]))
print(KNN.predict([[17, 21]]))
'CS > 머신러닝' 카테고리의 다른 글
| 혼자 공부하는 머신러닝 + 딥러닝 - Ch3-1 (0) | 2023.01.08 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 - Ch2 (0) | 2023.01.07 |
| 로지스틱 회귀 (0) | 2022.12.20 |
| 선형 회귀 - 경사 하강법 (0) | 2022.12.02 |
| 선형 회귀 - 최소제곱법 (0) | 2022.11.27 |


댓글